TL;DR
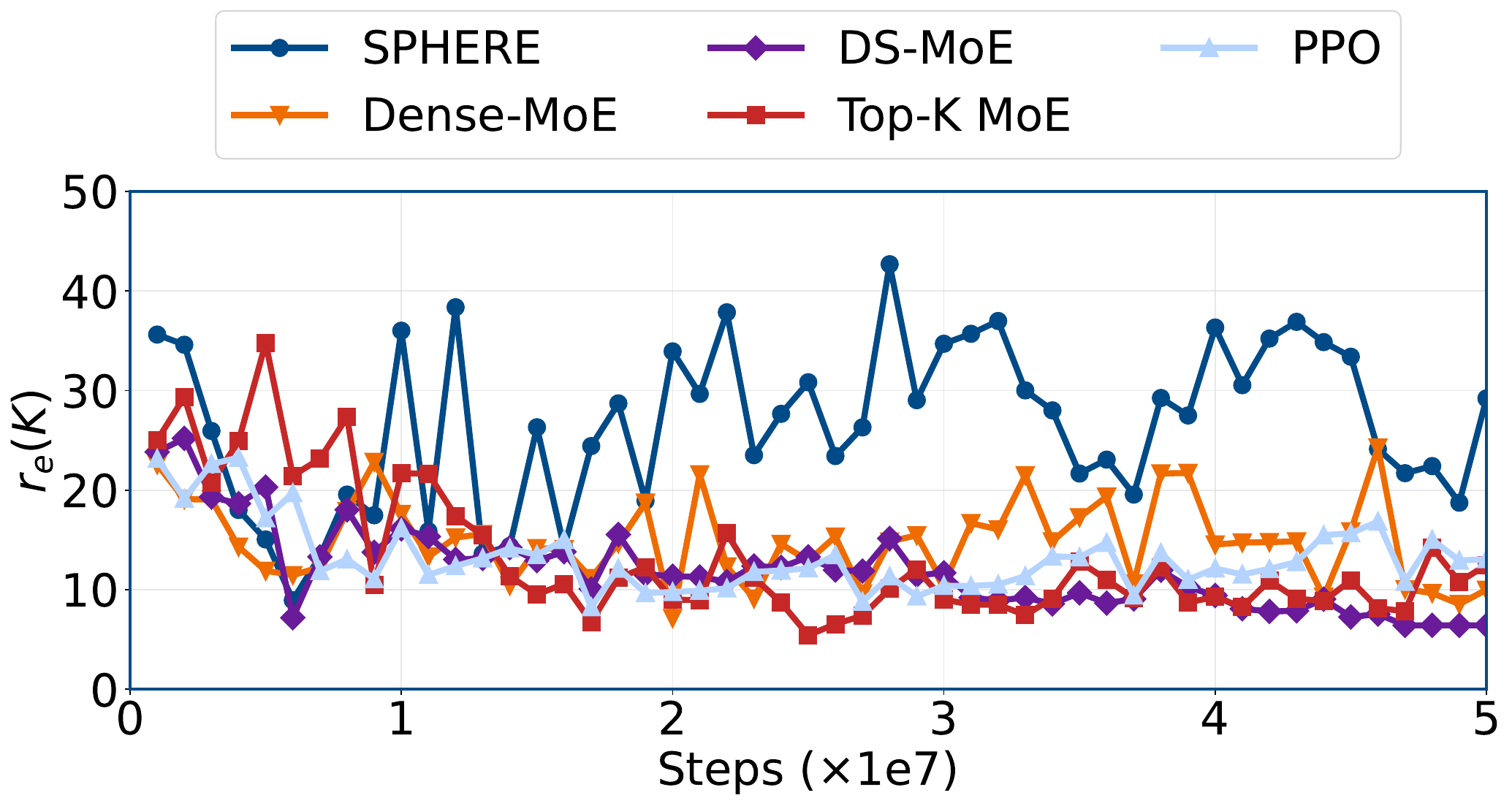
SPHERE studies why Mixture-of-Experts (MoE) policies lose their ability to adapt in continual RL. It shows that learning updates collapse into too few directions, then keeps expert features diverse so later tasks remain learnable.
Phenomenon → diagnosis → regularization
Problem
A policy trained across many tasks can stop adapting to later tasks.
Method
A regularizer that keeps expert features diverse instead of collapsed.
Result
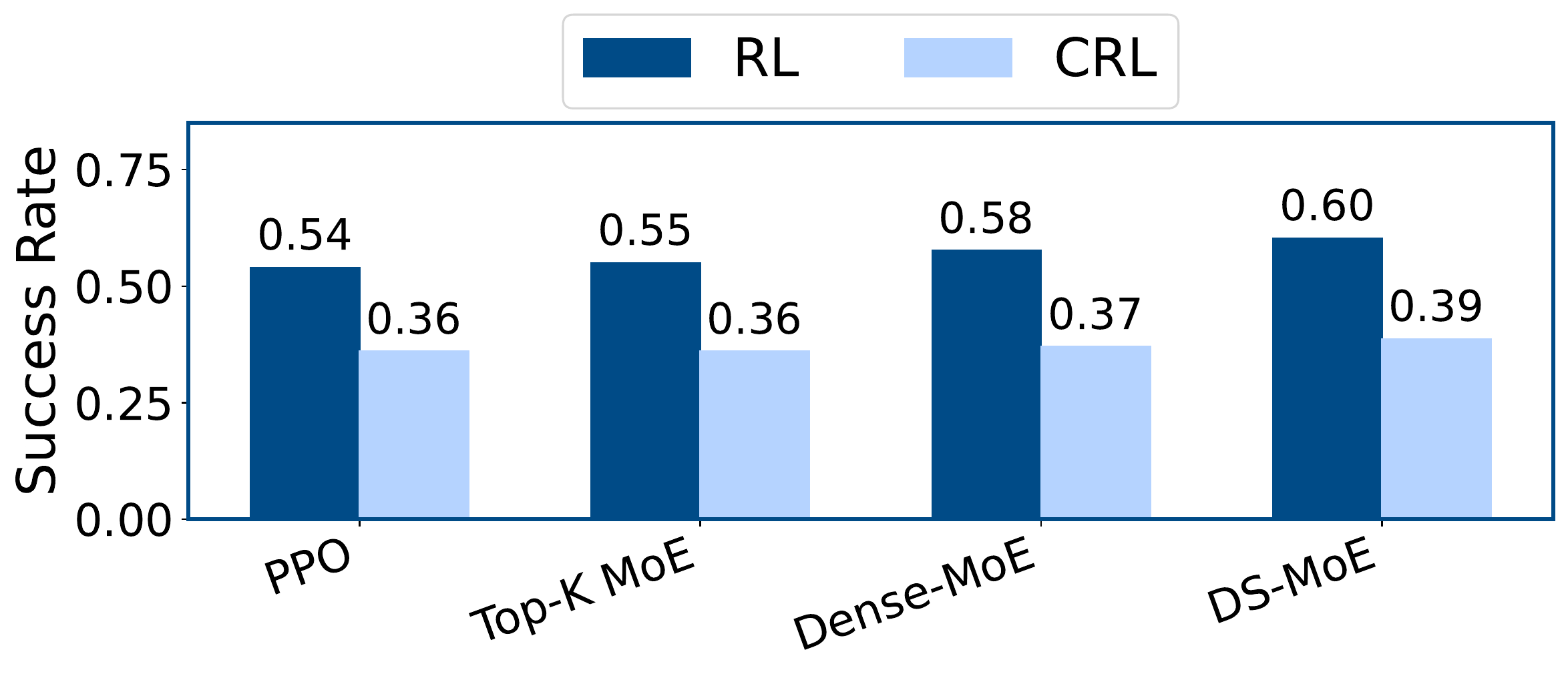
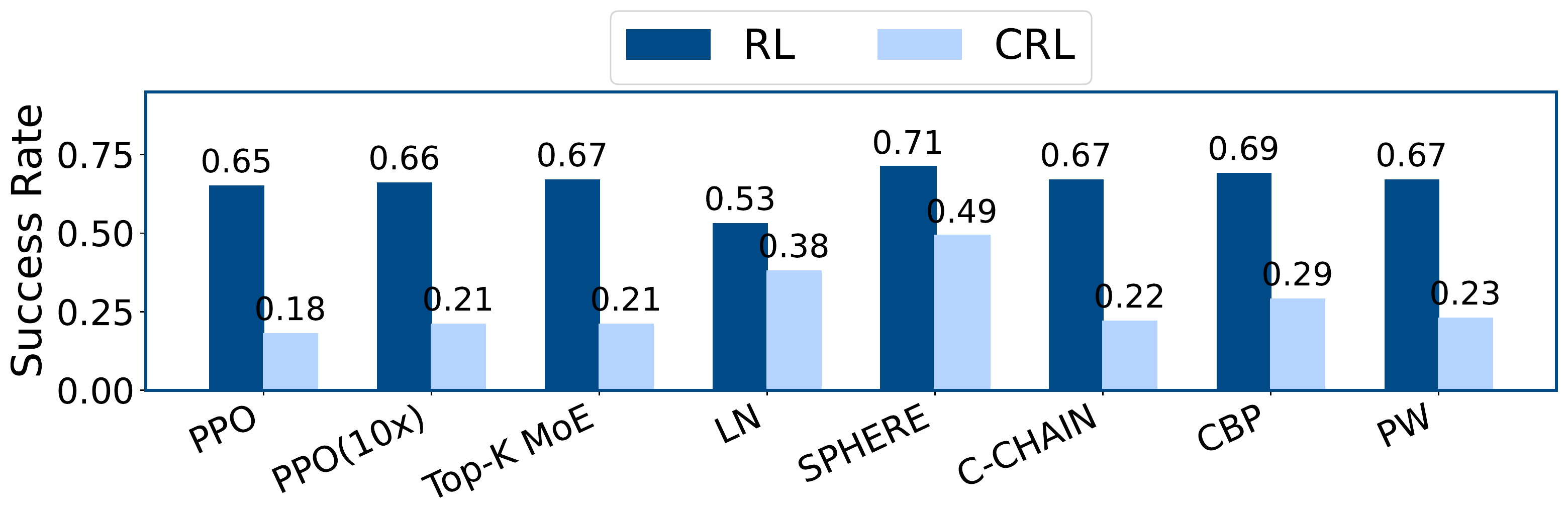
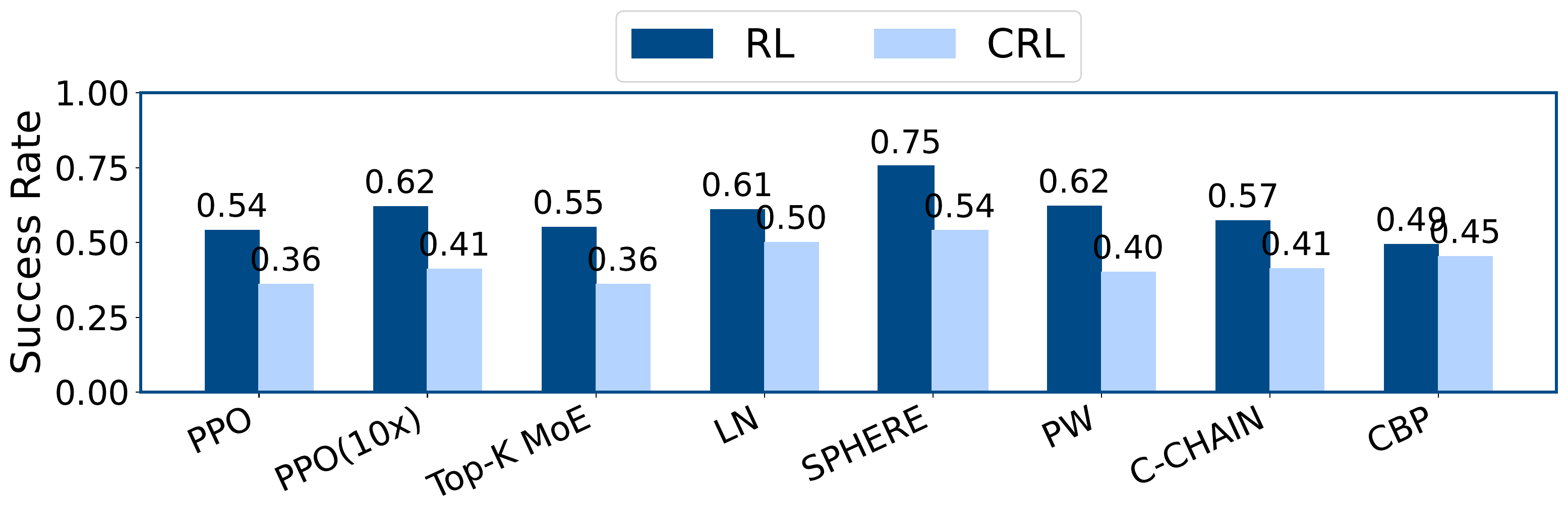
Better continual-control performance and healthier feature geometry across tasks.
Mechanism: Why Policies Stop Learning in Continual RL
The mechanism story starts with the observed learning slowdown, connects it to collapsed update directions, and then shows how SPHERE keeps those directions more diverse.
Phenomenon → spectral collapse → SPHERE
Update Geometry: Collapse vs. SPHERE
Use the slider · or press Play
The visualization makes the diagnosis concrete. A unit sphere of possible gradient directions becomes an ellipsoid after multiplication by the
empirical neural tangent kernel (eNTK) matrix K. When K becomes low-rank, one axis shrinks toward zero and the ellipsoid degenerates
toward a near-plane or line; SPHERE keeps the spectrum more isotropic.
Top row (∇fL) shows the input sphere of directions; bottom row
(K∇fL) shows the stretching process.
Real-data interactive panel
This interactive animation is generated from the underlying HumanoidBench experiment data used for Fig. 1. For each task, the
top-3 eigenvalues of K shape the ellipsoid, and gradient-direction samples
are projected into the same 3D eigenspace so the slider shows how the measured update geometry evolves.
Interactive 3D visualization comparing baseline Top-K MoE and SPHERE update geometry across HumanoidBench tasks.
Baseline (Top‑K MoE)
collapsed spectrum → near low-rank
SPHERE
isotropic spectrum → diverse updates
WebGL unavailable. Please use a WebGL-capable browser to see the 3D visualization.
BibTeX
@inproceedings{luo2026sphere,
title = {SPHERE: Mitigating the Loss of Spectral Plasticity in Mixture-of-Experts for Deep Reinforcement Learning},
author = {Luo, Lirui and Zhang, Guoxi and Xu, Hongming and Fang, Cong and Li, Qing},
booktitle = {Proceedings of the 43rd International Conference on Machine Learning},
year = {2026}
}